Sub-Microsecond Market Data Pipeline
Erstellt am: 14. April 2026
Eine Zero-Copy High-Frequency-Infrastruktur mit cache-alignten Shared-Memory-Strukturen, die Marktdaten in Echtzeit zu einem 8-Kanal Feature-Tensor anreichert – designed für Sub-Mikrosekunden-Latenz auf ARM64.
Das Kernproblem im algorithmischen Handel: Marktdaten sind wertlos, wenn sie den Verarbeitungspfad nicht in Echtzeit und ohne Memory-Overhead durchlaufen. Jeder Heap-Allocation, jeder Kopiervorgang, jede Cache-Line-Kollision kostet Nanosekunden – und Nanosekunden kosten Alpha.
Die Architektur folgt dem Prinzip der Mechanical Sympathy: Kein Garbage Collector berührt den kritischen Pfad, kein Betriebssystem-Syscall blockiert den Write. Der gesamte Datenstrom fließt durch ein Memory Mapped File im RAM () – zugänglich für alle Prozesse des Stacks ohne eine einzige Kopie.
Memory Map: Cache-Line-Aligned Shared Memory
Das Herzstück ist eine präzise segmentierte Speicherkarte, deren Grenzen und Struct-Größen explizit an die CPU-Architektur angepasst sind:
Drei Zonen mit definierten Offsets werden im Shared Memory adressiert:
Jeder Tick-Eintrag ist exakt 128 Byte groß – zwei volle Cache-Lines. Das eliminiert False Sharing: kein konkurrierender Read kann denselben Cache-Line-Block invalidieren, den der Writer gerade beschreibt. Der Zugriff auf den Ring Buffer erfolgt über eine lockfreie Modulo-Maske statt teurer Division:
Memory-Order Semantics via JDK 25 FFM (Project Panama)
Die Synchronisation zwischen Writer- und Reader-Prozessen erfolgt nicht über Locks, sondern über explizite Speicherbarrieren. Beim Writer garantiert setRelease(head_cursor + 1), dass alle vorangehenden Writes für jeden nachfolgenden Leser sichtbar sind, bevor der Cursor inkrementiert wird. Der Reader nutzt getAcquire(head_cursor), um Instruction-Reordering über den Lesepunkt hinaus zu verhindern. Dieses Acquire-Release-Paar implementiert das schwächstmögliche Synchronisationsprotokoll, das noch korrekt ist – stärker als Relaxed, schwächer als SeqCst, ohne einen einzigen Mutex.
8-Kanal Feature-Tensor
Parallel zum Raw-Tick schreibt die MathCore-Stufe einen vollständig angereicherten Feature-Vektor in denselben Struct-Slot:
Die Komponenten des Vektors sind mathematisch definiert: (Log-Return); (Rolling Realized Volatility); (Volatilitäts-Momentum); (Normalized Spread); (Order Book Imbalance); (Mean-Reversion-Potenzial); (Bid/Ask-Delta).
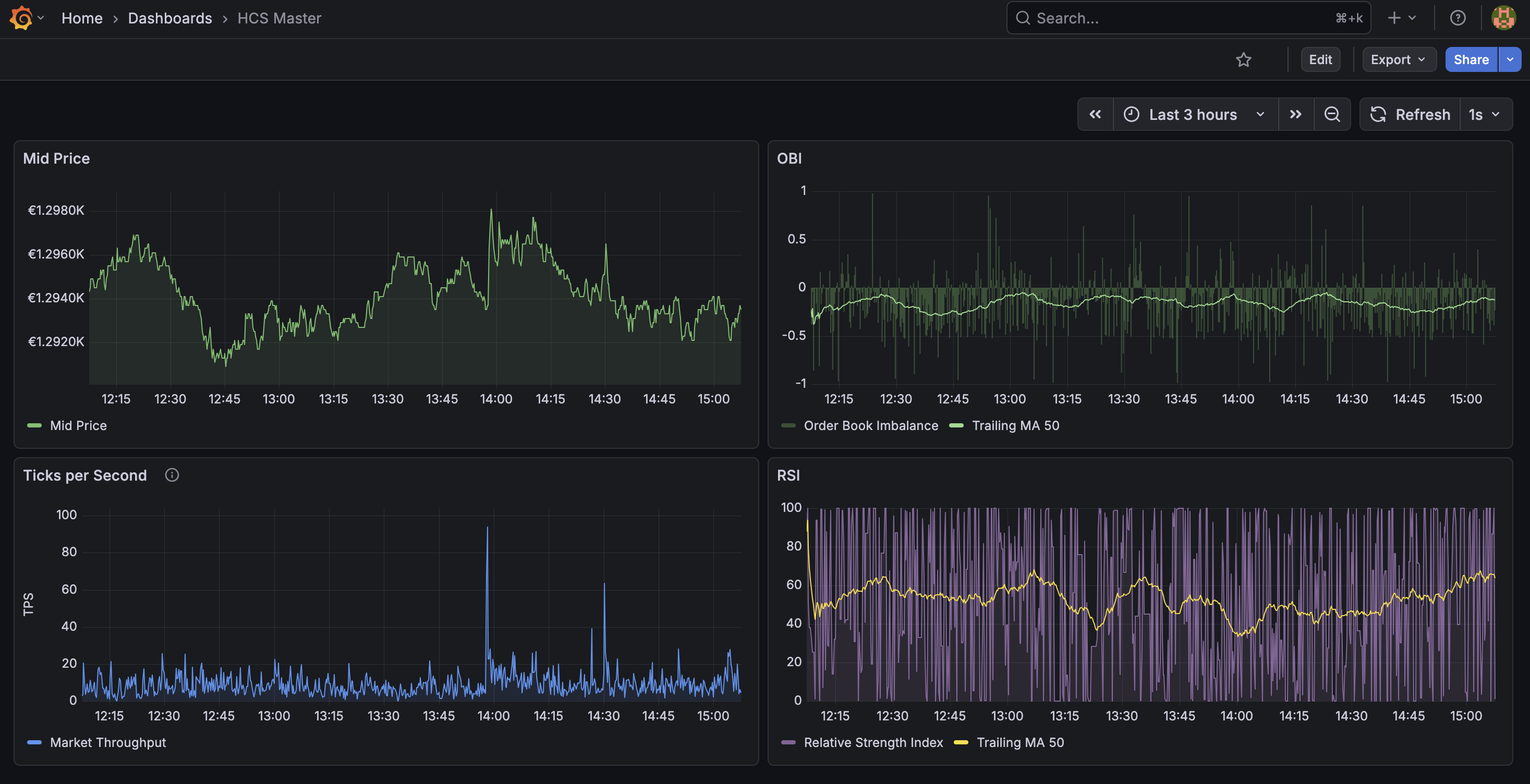
Dieser Tensor dient als primärer Input für den hcs-Signaldetektor, welcher auf archivierten Parquet-Snapshots trainiert wird und dessen Inferenz direkt auf dem Live-Stream operiert.
Deployment: ARM64 + Docker + Zero-GC-Path
Die JVM wird mit ZGC und festem Heap (-Xms2G -Xmx2G) betrieben, um GC-Pausen vollständig aus dem kritischen Pfad zu eliminieren. Auf Raspberry Pi 5 ermöglicht ipc: host im Docker-Compose-Stack den direkten Shared-Memory-Zugriff über Prozessgrenzen hinweg. Prometheus und Grafana liefern Echtzeit-Metriken auf OBI, Micro-Price und Volatilität.